It's Time to Rethink Old Ideas with New Solutions
Mar 04, 2021

If you always do what you've always done, you will always get what you've always got. Sound familiar? Like many quotes, this one is simple yet powerful. Many people have laid claim to this quote including Anthony Robbins and before him Albert Einstein, Henry Ford, and even Mark Twain. Regardless, what matters is the point it makes.

The premise is if you want different, and ideally, better results, you may need to change how you're doing things. Seems like a no-brainer, right?
Now, think of this in the context of executing or supporting projects and enterprise systems within your organization. Businesses frequently fail to embrace a culture of change and innovation, particularly in tough times, and often, even known problems or issues may continue to persist – or be repeated without a pause for consideration of whether there's a better way of doing things to strive for better results.
Any enterprise system that has been in use for any length of time could likely benefit from data cleanup, reorganization, or normalization. Asset Maintenance systems like IBM Maximo, are potentially even more so – particularly if they are also integrated with other systems, like a financial ERP. Changes to asset information, cost centers, GL codes, vendors, etc. are part of normal business that drive the need for periodic data updates – but other organizational evolutions, such as changes to core business processes, acquisitions and divestitures or mergers, and even routine system utilization over time can create a need to perform data cleanup and normalization, rework hierarchies, and even archive data.
Historically, these types of data projects were time-consuming and costly, required large amounts of manual effort using technical data resources, took months (or years) to perform, and were inflexible and cumbersome to the organization.
Fortunately, the tools have evolved to tackle the data age head-on, and a powerhouse data solution like Alchemize™ is reinventing how you can solve your EAM data challenges. In fact, at Ascension, we are even scoping our data projects using Alchemize as our standard to flatten the curve on the risk, timeline, variability, and cost of data projects. Check out our case studies using Alchemize and you'll see why.
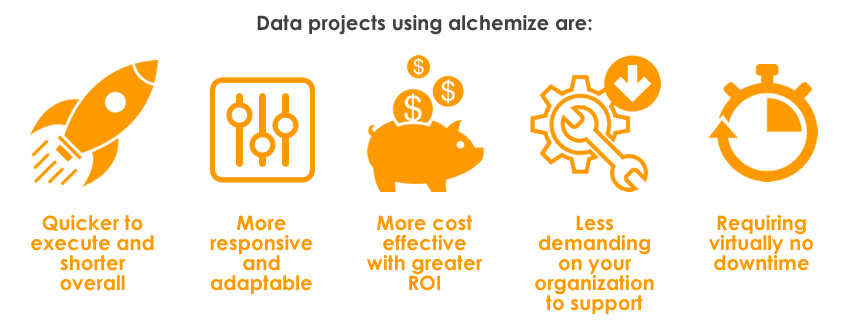
Alchemize is a single management platform software solution that intelligently automates manual processes involved in data mapping, discovery, and processes. We know from years of experience, that this data mapping process is often the most time consuming and expensive portion of any data project activities and can take weeks, or even months depending on the project. Through this automation, Alchemize simplifies, standardizes, and reduces the time & risks involved with data quality projects, such as cleansing, purging, normalizing, and archiving, thereby also significantly reducing the demand on resources, timelines, and budgets by up to 80%!
To help illustrate these points, we have assembled a comparison of the primary activities associated with nearly every data project, using Alchemize versus a traditional data model involving typical data resources, from our over two decades of experience in scoping and executing Maximo projects. Each activity is measured both as a level of effort and duration, and with a scale of risk and variables.
Data Projects Comparative Analysis
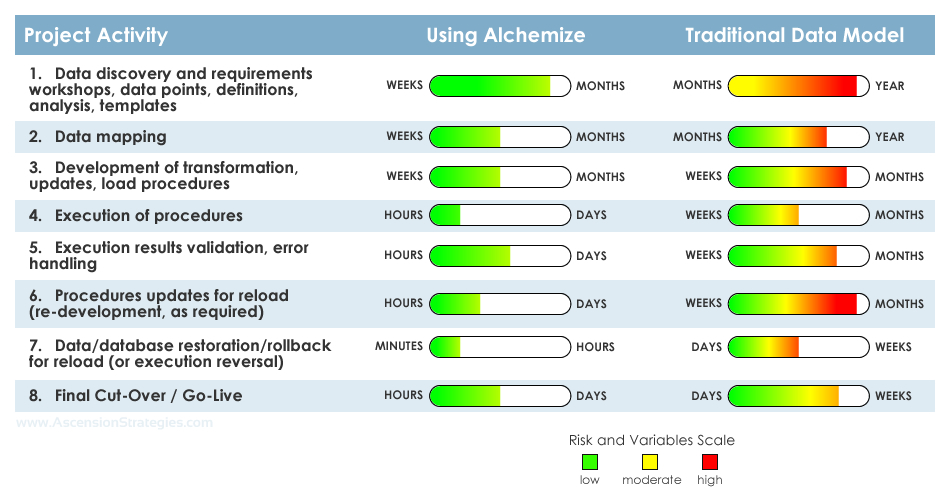
Project Activities Overview
- Data discovery and requirements workshops, data points, definitions, analysis, templates
The tasks associated with this activity are typically the longest to perform for nearly every data project, and for the traditional data model involve significant manual effort that is frequently fraught with higher risk and variables, as well as inconsistency between data resources, and usually starting every time "from scratch". With Alchemize, we can actually start by using the built-in functionality to systematically map the legacy and target systems (where applicable), resulting in ~90% of the initial data mapping done to serve as the starting point to base the remaining requirements workshops, discovery, etc. on – thereby reducing not only the time required, but the manual effort, risk and variables. - Data mapping
Within the traditional data model, this manual activity typically takes place after all of the requirements and discovery workshop tasks and requires significant time and effort. On an Alchemize project, this would entail needing to only make updates to append the initial systematic mapping with missing or additional data identified during the requirements and discovery workshop tasks. - Development of transformation/update/load procedures
For the traditional data model, this activity frequently means manually building scripts "from scratch" to perform the data loading, updating, or any transformation/handling. Within Alchemize this is accomplished by building intelligent "jobs" to programmatically perform the data loading, updating, or any transformation/handling – and which can be easily updated/modified, automated, and re-run. - Execution of procedures
Alchemize's automated features allow multiple "jobs" to be scheduled and run in parallel, resulting in the ability to perform data loads, updates, and transformations much quicker than traditional data model running of scripts or database procedures – with virtually zero downtime. What takes hours to days in a traditional data model takes only minutes to hours using Alchemize! - Execution results validation and error handling
While some level of user validation should be included with both Alchemize and traditional data model projects, manual data projects often have very little ability to self-perform any systematic data validation for error handling and is typically a manual effort with low levels of detail provided, instead relying on system users to report any issues or errors. Alchemize can produce load and error reports prior to requiring user testing, and also offers the ability to preview a data load, update, or transformation to assess the results – which can then be quickly and easily updated and re-run without needing traditional data model data/database restoration or rollback efforts, resulting in an ability for rapid deployment, updating, and testing/re-testing, without the lengthy "re-work" typically required in a traditional data model. - Procedures updates for reload (re-development, as required)
Updating the data procedures (scripts, etc.) within a traditional data model, in addition to being labor and time intensive, can frequently require up to 100% rebuild of the scripts and load routines. Add to this potentially also needing to perform data/database restoration or rollback prior to being able to reload, and this activity that may require multiple iterations can quickly bog down a project – as well as running into issues with maintaining update versions and traceability towards developing a final repeatable process for go-live. Alchemize "jobs" may be quickly and easily updated, previewed and tested, saved in versions, and rapidly deployed multiple times without requiring restoration or rollback procedures. - Data/database restoration/rollback for reload (or execution reversal)
Within the traditional data model, the need for data/database restorations or rollbacks for reloading of data routines usually involves more complex activities and requires lengthy outages and additional support from various areas within your organization – each and every time! Alchemize can self-manage any data/database restorations or rollbacks without any additional support or downtime from your organization and quickly re-run updates and validation. Did you ever wish there was an "undo" button for data loading? With Alchemize, there is! - Final Cut-Over / Go-Live
The same automated streamlined execution with Alchemize results in the final data loading, updating, and transformation leveraging all of the load procedures, validation and error handling developed and refined during the prior activities to achieve production-readiness with virtually no risk and zero downtime. Should any errors or issues arise during the final load, Alchemize "jobs" may be quickly reverted, updated, and re-run prior to impacting post implementation utilization – whereas the traditional model requires the same manual execution efforts, long system outages and downtime, and any possible error handling resulting in lengthy rework which may impact production readiness or require post-implementation adjustments.
To add another check in "win" column, Alchemize offers flexible license options; either as an on-going enterprise solution capacity or as Software-as-a-Service (SaaS) for one-time projects. By adding Alchemize to your organization's toolkit, you can reduce costs and increase efficiency – along with reducing the demand on your IT Department, arming your data management team with the tools to be successful, and providing repeatable and streamlined solutions for a host of data project scenarios – all while also updating historical information to retain referential integrity!
Alchemize can solve all of these data project challenges (and more)!
Contact us today for a no-obligation discussion to find out how we can help solve your data projects challenges and make Alchemize part of your organizations long-term solutions road map.
Recent Posts
- End of Support (EoS) for Maximo 7.6.0.x is on the Horizon — Ready to Upgrade?
- It's Time to Rethink Old Ideas with New Solutions
- Reviewing your IBM Maximo license utilization for audit compliance and potential cost savings has never been easier with HALO™
- The new remote workforce is coming - is your organization ready?
- Working from home? Try these 9 keys to success!
- Do Remote Consultants Provide the Same Value as Onsite Collaborations?
- What are Maximo Work Centers and Are They Worth the Hype?
- Got Data? It's time to Alchemize
- Top 10 Reasons to Upgrade in the New Year
- The Dirty Dozen - Maximo Questions You Should be Asking
- Want your project to succeed? Ask yourself these questions
- How to Overcome Today's Top Support Challenges
- Anatomy of change management - Part 1: Let's get technical
- Anatomy of change management - Part 2: The human factor
- Don't Start Without A Solid Plan for your next TECH Project
- Extending Maximo to the Field Service Teams
- Why Upgrade Your Maxixmo?
- Delivering Continuous Return on Investment (ROI) with IBM Maximo
Not Getting Our Posts and Industry News?
